コラム
テキスト型データ解析とグループインタビューの発言録
グループインタビューの発言録を定量的に解析してみたいとの考えは以前からありました。
「WordMiner」というソフトウエアが30万円と聞いて導入を考え、9月11日に行われたシンポジウム
日本分類学会・日本行動計量学会共催 シンポジウム |
を聞いてきました。
その結果は、
30万円でも、導入は時期尚早 |
ということになりました。
理由は「マイニング」という思想そのものにあるので「WordMiner」だけでなく他のソフトも同じことですし、 シンポジウムを聞くまでもないことではありました。
どのソフトも基本は以下の図式です。
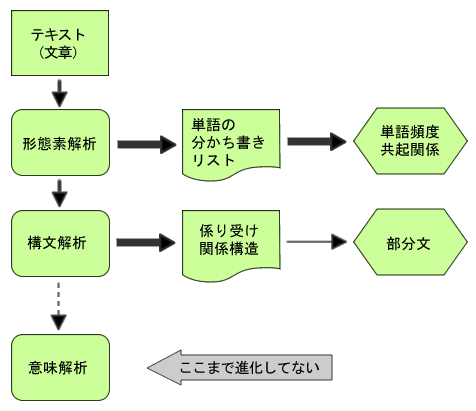
発言録にある対象者の発言(テキスト)は全て同じウエイトで扱われます。
しかし、インタビューの現場では、「好き、買いたい」の発話が対象者AとBから出たとしてもウエイトが 大きく異なることは明白です。
それを「単語頻度」と「共起関係」で計量されても困ります。
やはり、定量調査の「自由回答文」のように限定された意味範囲で大量のテキストが発生する状況でしか 使えそうもありませんでした。
今回のシンポジウムでは4つのソフトウエアでの解析結果が紹介されましたが、その中で電通リサーチの 「DE-FACTO」がおもしろい、使えそうな印象を持ちました。
(ただ、外販はしないそうです。)
その設計思想をひとことで言うと
| KJ法の機械化 |
です。
元のテキストを無闇にバラバラにしないのがよいところです。
アウトプットもマーケティングの分析・報告に使えそうです。
